Python散列表
散列表
散列表是一种数据的集合,其中的每个数据都通过某种特定的方式进行存储以方面日后的查找。基于它的搜索算法的时间复杂度为O(1)。散列表的每一个位置叫做槽,能够存放一个数据项,并以从0开始递增的整数命名。例如, 第一个槽记为0,下一个记为1,再下一个记为2,并以此类推。在初始条件下,散列表中是没有任何数据的,即每个槽都是空的。某个数据项与在散列表中存储它的槽之间的映射叫做散列函数。一般地,我们把槽被占据的比例叫做负载因子,两个甚至多个数据需要存储在同一个槽中,这种情况被称为冲突。
散列函数
对于一组给定的数据项,如果一个散列函数可以将每一个数据项都映射到不同的槽中,那么这样的散列函数叫做完美散列函数。一种实现完美散列函数的方法就是扩大散列表的尺寸,直到所有可能的数据项变化范围都被散列表所包含。这一方法保证了每一个数据项都有一个不同的槽。尽管这个方法对于少量数据是可行的,但是当它面对大量可能的数据项时显得捉襟见肘。
我们的目标是创建一个能够将冲突的数量降到最小,计算方便,并且最终将数据项分配到散 列表中的散列函数。有几种普通的方法去扩展求余方法:
- 折叠法:首先将数据分成相同长度的片段(最后一个片段长度可能不等)。接着将这些片段相加,再求余得到其散列值。
- 平方取中法:我们首先将数据取平方,然后取平方数的某一部分,然后再进行求余运算。
我们也可以为非数字的数据项,例如字符串创建散列表,’cat’可以看做一个连续的ASCII数值。1
2
3
4
5
6# 用ASCII数值散列一个字符串
def hash(astring, tablesize):
sum = 0
for i in range(len(astring)):
sum = sum + ord(astring[i])
return sum%tablesize
当我们用散列函数纪录散列值的时候,颠倒的字母构成的单词会得到相同的散列值。为了纠正这一情况,我们可以将字母的位置作为权重因子。1
2
3
4
5
6# 用ASCII数值*权重散列一个字符串
def hash(astring, tablesize):
sum = 0
for i in range(len(astring)):
sum = sum + ord(astring[i])*(i+1)
return sum%tablesize
冲突
当两个数据散列到相同的槽,我们必须用一种系统化的方法将第二个数据放到散列表里。这个过程叫做冲突解决。
- 一种解决冲突的方法就是搜索散列表并寻找另一个空的槽来存放这个有冲突的数据。一种简单的方法就是从发生冲突的位置开始顺序向下开始寻找,直到我们遇到第一个空的槽。注意到我们可能需要回到第一个槽(循环)来实现覆盖整个散列表。这种冲突解决方法叫做开放地址,它试图在散列表中去寻找下一个空的槽。通过系统地向后搜索每一个槽,我们将这种实现开放地址的技术叫做线性探测。

- 线性探测法的一个缺点是产生集中的趋势:数据会在表中聚集。这意味着如果对于同一散列值产生了许多冲突时,周边的一系列槽都将会被线性探测填充。这将会对正在被填入的新数据产生影响。一种解决集中问题的方法是扩展线性探测技术,我们不再按顺序一个一个地寻找新槽,而是跳过一些槽,这样能更加平均地分配出现冲突的数据,进而潜在地减少集中问题出现的次数。下图展示了同样的数据项如何通过“+3”线性探测的方法解决冲突的。“+3”表示一旦一个冲突出现,我们将每次跳过两个槽来寻找下一个新的空槽。

- 另一种线性探测方法叫做二次探测法。我们不是每次在冲突中选择跳过固定个数的槽,而是使用一个再散列函数使每次跳过槽的数量会依次增加1,3,5,7,9,以此类推。这意味着如果原槽为第h个,那么再散列时访问的槽为第h+1,h+4,h+9,h+16个,以此类推。换言之,二次探测法使用一个连续的完全平方数数列作为它的跳跃值。图11显示了我们的例子在运用二次探测法时的 填充结果。

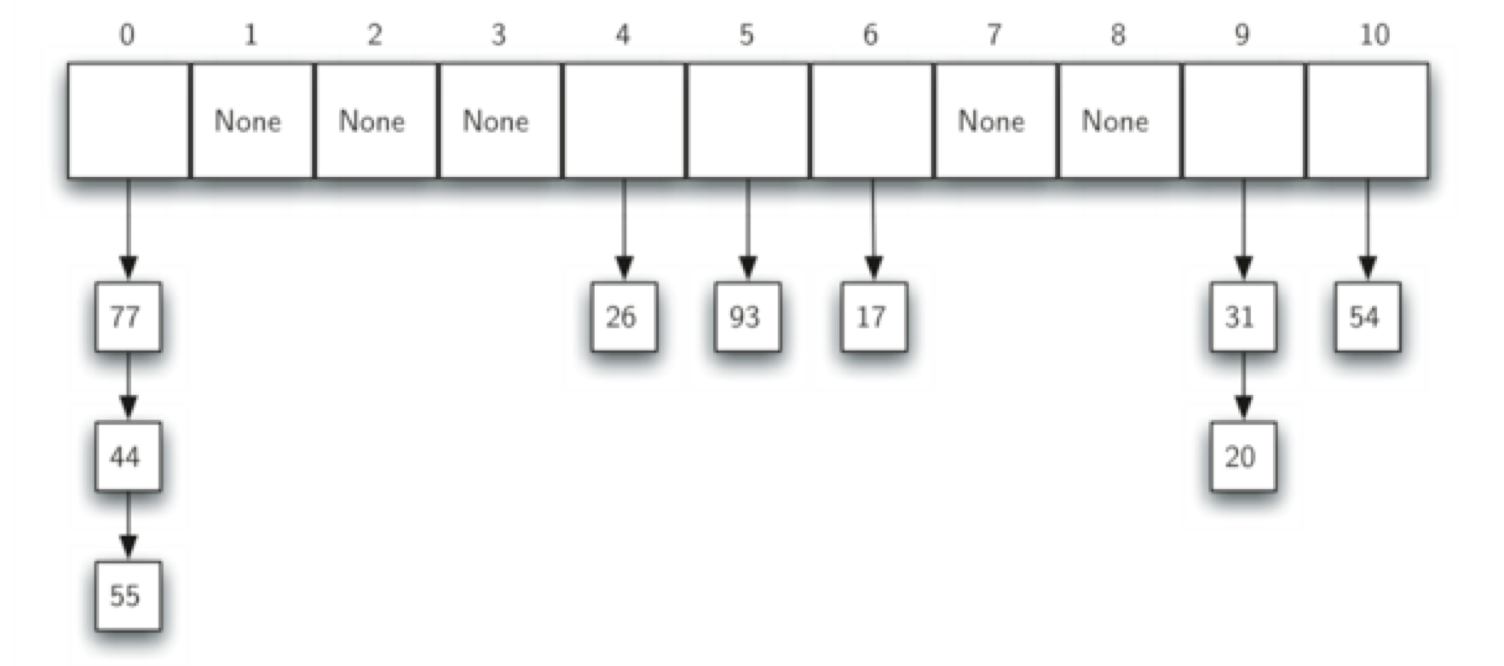
- 另一个解决冲突的替代方法是允许每一个槽都能填充一串而不是一个数据(称作链)。链能允许多个数据填在散列表中的同一个位置上。当冲突发生时,数据还是填在本应该位于的槽中。 随着一个槽中填入的数据的增多,搜索的难度也就随之增加。下图显示了数据在用数据链方法填入散列表的结果。
实现映射的抽象数据类型
字典是Python中最有用的数据类型之一。字典是一个可以储存键-值对的关联数据类型。键是用来查找和它相关联的值的。通常把这个想法称作映射。映射的抽象数据类型定义如下:它以一个键与一个值之间关联的无序集合作为结构。映射中的键都是独特的,以保证和值之间的一一对应关系。
映射的相关操作:
- Map():产生一个新的空映射
- put():往映射中添加键-值对。如果密钥已经存在,那么将旧的数据值置换为新的。
- get(key):给定一个 key 值,返回关联的数据,若不存在,返回None。
- del:从映射中删除一个密钥-数据值对,声明形式为del map[key]。
- len():返回映射中的存储密钥-数据值对的个数。
- in:表述为key in map,如果给定的键在map中返回True,否则返回False。
python实现映射1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58# 创建哈希表类
class Hashtable():
def __init__(self):
self.size = 11
# 定义两个列表分别存储键和值
self.slots = [None]*self.size
self.data = [None]*self.size
# 定义put()方法
def put(self, key, data):
hashvalue = self.hashFunc(key, len(self.slots)) # hashvalue为计算出的一个整数,此处相当于列表的下标
if self.slots[hashvalue] == None: # 创建新的键值对
self.slots[hashvalue] = key
self.data[hashvalue] = data
else:
if self.slots[hashvalue] == key: # 该键的位置没有被rehash过,重新赋予键新值
print('***', hashvalue, self.slots[hashvalue], key)
self.data[hashvalue] = data
else: # 该键的位置被rehash过,重新赋予键新值
nextslot = self.rehash(hashvalue, len(self.slots))
while self.slots[nextslot] != None and self.slots[nextslot] != key:
nextslot = self.rehash(nextslot, len(self.slots))
if self.slots[nextslot] == None:
self.slots[nextslot] = key
self.data[nextslot] = data
else:
self.data[nextslot] = data
# 定义hashFunc()方法
def hashFunc(self, key, size):
return key%size
# 定义rehash()方法
def rehash(self, oldvalue, size):
return (oldvalue + 1)%size
# 定义get()方法
def get(self, key):
initslot = self.hashFunc(key, len(self.slots))
data = None
stop = False
found = False
pos = initslot
while self.slots[pos] != None and not found and not stop:
if self.slots[pos] == key:
found = True
data = self.data[pos]
else:
pos = self.rehash(pos, len(self.slots))
if pos == initslot: # 循环到开始处,表示没有搜索到
stop = True
return data
def __getitem__(self, key):
return self.get(key)
def __setitem__(self, key, data):
self.put(key, data)